
Tag: Prototypes
RAPID PROTOTYPING OF DIGITAL SYSTEMS: A TUTORIAL APPROACH
By James O. Hamblen and Michael D. Furman, Kluwer Academic Publishers, 2000.
This book provides an exciting and chal- lenging laboratory component for an un- dergraduate student as well as design engineers working in industry. It intro- duces the field programmable logic device (FPLD) technology and logic synthesis us- ing CAD tools. The book is organized in 13 chapters as follows. Chapter 1 provides a tutorial for CAD tools that covers the de- sign entry, simulation, and hardware im- plementation using an FPLD. Chapter 2 provides an overview of the UP1 FPLD de- velopment board, where the features of the board are briefly described. Chapter 3 introduces the programmable logic tech- nology where the most common complex programmable logic device (CPLD) and field programmable gate array (FPGA) are presented. Chapter 4 is a tutorial to use both a hierarchical and sequential design with different examples. Chapter 5 de- scribes the UP1core library I/O functions. Chapter 6 introduces the use of VHDL for the synthesis of digital hardware. Chapter 7 describes a state machine that controls a virtual electric train system simulation with video output generated directly by the CPLD. Chapter 8 develops a VHDL model of a simple computer where a fetch, decode, and execute cycle is simulated.
CIRCUITS & DEVICES s NOVEMBER 2001
39 s
Chapter 9 describes how to design an FPLD-based digital system to output VGA video. Chapter 10 describes the PS/2 key- board operation and presents interface ex- amples for integration in designs on the UP1 board. Chapter 11 describes the PS/2 mouse operation and presents interface examples for integration in designs on the UP1 board. Chapter 12 develops a design for an adaptable mobile robot using the UP1 board. Chapter 13 describes a single clock cycle model of the MIPS RISC pro- cessor. The book also includes a large number of laboratory problems and a vari- ety of design projects at the end of each chapter.
The book comes with the new student version of Altera’s MAX+PLUS II CAD tool and the UP1 board is available from Altera at special student pricing.
This is an ideal book for undergraduate digital logic and computer design courses with more than 40 fully developed and simulated examples that can be used on the UP1 board.
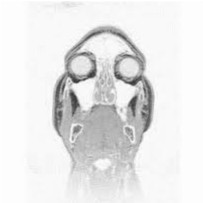
MRI Data Compression Using a 3-D Discrete Wavelet transform
A low-power system that can be used to compress MRI data and for other medical applications is described. The system uses a low power 3-D DWT processor based on a centralized control unit architecture. The simulation results show the efficiency of the wavelet processor. The prototype processor consumes 0.5 W with total delay of 91.65 ns. The processor operates at a maximum frequency of 272 MHz. The prototype processor uses 16-bit adder, 16-bit Booth multiplier, and 1 kB cache with a maximum of 64-bit data bandwidth. Lower power has been achieved by using low-power building blocks and the minimal number of computational units with high throughput.
Published in:
Engineering in Medicine and Biology Magazine, IEEE (Volume:21 , Issue: 4 )
- Page(s):
- 95 – 103
- ISSN :
- 0739-5175
- INSPEC Accession Number:
- 7389345
- DOI:
- 10.1109/MEMB.2002.1032646
- Date of Publication :
- Jul/Aug 2002
- Date of Current Version :
- 07 November 2002
- Issue Date :
- Jul/Aug 2002
- Sponsored by :
- IEEE Engineering in Medicine and Biology Society
- Publisher:
- IEEE
Wael Badawy, Guoqing Zhang, Mike Talley, Michael Weeks and Magdy Bayoumi, “MRI Data Compression Using a 3-D Discrete Wavelet transform,” The IEEE Engineering in Medical and Biology Magazine, Vol. 21, Issue 4, July/August 2002, pp. 95-103.

An Affine Based Algorithm and SIMD Architecture for Video Compression with Low Bit-rate Applications
This paper presents a new affine-based algorithm and SIMD architecture for video compression with low bit rate applications. The proposed algorithm is used for mesh-based motion estimation and it is named mesh-based square-matching algorithm (MB-SMA). The MB-SMA is a simplified version of the hexagonal matching algorithm [1]. In this algorithm, right-angled triangular mesh is used to benefit from a multiplication free algorithm presented in [2] for computing the affine parameters. The proposed algorithm has lower computational cost than the hexagonal matching algorithm while it produces almost the same peak signal-to-noise ratio (PSNR) values. The MB-SMA outperforms the commonly used motion estimation algorithms in terms of computational cost, efficiency and video quality (i.e., PSNR). The MB-SMA is implemented using an SIMD architecture in which a large number of processing elements has been embedded with SRAM blocks to utilize the large internal memory bandwidth. The proposed architecture needs 26.9 ms to process one CIF video frame. Therefore, it can process 37 CIF frames/s. The proposed architecture has been prototyped using Taiwan Semiconductor Manufacturing Company (TSMC) 0.18-μm CMOS technology and the embedded SRAMs have been generated using Virage Logic memory compiler.
Published in:
Circuits and Systems for Video Technology, IEEE Transactions on (Volume:16 , Issue: 4 )
- Page(s):
- 457 – 471
- ISSN :
- 1051-8215
- INSPEC Accession Number:
- 8891917
- DOI:
- 10.1109/TCSVT.2006.872780
- Date of Publication :
- April 2006
- Date of Current Version :
- 01 May 2006
- Issue Date :
- April 2006
- Sponsored by :
- IEEE Circuits and Systems Society
- Publisher:
- IEEE
Back to a complete list of Peer-Reviewed Journal Papers
Mohammed Sayed , Wael Badawy, “An Affine Based Algorithm and SIMD Architecture for Video Compression with Low Bit-rate Applications“, IEEE Transactions on Circuits and Systems for Video Technology, Vol. 16, Issue 4, pp. 457-471, April 2006. Abstract

CAVLC Encoder Design for Real-Time Mobile Video Applications
Abstract
This brief presents a new context-based adaptive variable length coding (CAVLC) architecture. The prototype is designed for the H.264/AVC baseline profile entropy coder. The proposed design offers area savings by reducing the size of the statistic buffer. The arithmetic table elimination technique further reduces the area. The split VLC tables simplify the process of bit-stream generation and also help in reducing some area. The proposed architecture is implemented on Xilinx Virtex II field-programmable gate array (2v3000fg676-4). Simulation result shows that the architecture is capable of processing common/quarter-common intermediate format frame sequences in real-time at a core speed of 50 MHz with 6.85-K logic gates.
Published in:
Circuits and Systems II: Express Briefs, IEEE Transactions on (Volume:54 , Issue: 10 )
- Page(s):
- 873 – 877
- ISSN :
- 1549-7747
- INSPEC Accession Number:
- 9633945
- DOI:
- 10.1109/TCSII.2007.902215
- Date of Publication :
- Oct. 2007
- Date of Current Version :
- 15 October 2007
- Issue Date :
- Oct. 2007
- Sponsored by :
- IEEE Circuits and Systems Society
- Publisher:
- IEEE
C. A. Rahman and W. Badawy, “CAVLC Encoder Design for Real-time Mobile Video Applications”, The IEEE Trans. on Circuits and Systems II, Oct. 2007 Vol 54, Issue: 10, pp. 873-877.
Link to the list of other Peer Journal Publications