
Tag: MPEG-4
A Multiplication-Free Algorithm and A Parallel Architecture for Affine Transformation
Affine transformation is widely used in image processing. Recently, it is recommended by MPEG-4 for video motion compensation. This paper presents a novel low power parallel architecture for texture warping using affine transformation (AT). The architecture uses a novel multiplication-free algorithm that employs the algebraic properties of the AT. Low power has been achieved at different levels of the design. At the algorithmic level, replacing multiplication operations with bit shifting saves the power and delay of using a multiplier. At the architecture level, low power is achieved by using parallel computational units, where the latency constraints and/or the operating latency can be reduced. At the circuit level, using low power building blocks (such as low power adders) contributes to the power savings. The proposed architecture is used as a computational kernel in video object coders. It is compatible with MPEG-4 and VRML standards. The architecture has been prototyped in 0.6 μm CMOS technology with three layers of metal. The performance of the proposed architecture shows that it can be used in mobile and handheld applications.
Wael Badawy and Magdy Bayoumi, “A Multiplication-Free Algorithm and A Parallel Architecture for Affine Transformation,” The Journal of VLSI Signal Processing-Systems, Kluwer Academic Publishers, Vol. 31, No 2, May 2002, pp. 173-184.

A new time distributed DCT architecture for MPEG-4 hardware reference model
This paper presents the design of a new time distributed architecture (TDA) which outlines the architecture (ISO/IEC JTC1/SC29/WG11 MPEG2002/M8565) submitted to MPEG4 Part9 committee and included in the ISO/IEC JTC1/SC29/WG11 MPEG2002/9115N document. The proposed TDA optimizes the two-dimensional discrete cosine transform (2-D-DCT) architecture performance. It uses a time distribution mechanism to exploit the computational redundancy within the inner product computation module. The application specific requirements of input, output and coefficients word length are met by scheduling the input data. The coefficient matrix uses linear mappings to assign necessary computation to processor elements in both space and time domains. The performance analysis shows performance savings in excess of 96% as compared to the direct implementation and more than 71% as compared to other optimized application specific architectures for DCT.
Published in:
Circuits and Systems for Video Technology, IEEE Transactions on (Volume:15 , Issue: 5 )
- Page(s):
- 726 – 730
- ISSN :
- 1051-8215
- INSPEC Accession Number:
- 8422879
- DOI:
- 10.1109/TCSVT.2005.846429
- Date of Publication :
- May 2005
- Date of Current Version :
- 02 May 2005
- Issue Date :
- May 2005
- Sponsored by :
- IEEE Circuits and Systems Society
- Publisher:
- IEEE
Alam, M.; Badawy, W.; Jullien, G.; “A new time distributed DCT architecture for MPEG-4 hardware reference model,” IEEE Circuits and Systems for Video Technology, Volume 15, Issue 5, May 2005, pp. 726 – 730.
Algorithm-Based Low Power VLSI Architecture For 2d-Mesh Video Object Motion Tracking
The new VLSI architecture for video object (VO) motion tracking uses a novel hierarchical adaptive structured mesh topology. The structured mesh offers a significant reduction in the number of bits that describe the mesh topology. The motion of the mesh nodes represents the deformation of the VO. Motion compensation is performed using a multiplication-free algorithm for affine transformation, significantly reducing the decoder architecture complexity. Pipelining the affine unit contributes a considerable power saving. The VO motion-tracking architecture is based on a new algorithm. It consists of two main parts: a video object motion-estimation unit (VOME) and a video object motion-compensation unit (VOMC). The VOME processes two consequent frames to generate a hierarchical adaptive structured mesh and the motion vectors of the mesh nodes. It implements parallel block matching motion-estimation units to optimize the latency. The VOMC processes a reference frame, mesh nodes and motion vectors to predict a video frame. It implements parallel threads in which each thread implements a pipelined chain of scalable affine units. This motion-compensation algorithm allows the use of one simple warping unit to map a hierarchical structure. The affine unit warps the texture of a patch at any level of hierarchical mesh independently. The processor uses a memory serialization unit, which interfaces the memory to the parallel units. The architecture has been prototyped using top-down low-power design methodology. Performance analysis shows that this processor can be used in online object-based video applications such as MPEG-4 and VRML
Wael Badawy and Magdy Bayoumi, “Algorithm-Based Low Power VLSI Architecture For 2d-Mesh Video Object Motion Tracking,” The IEEE Transaction on Circuits and Systems for Video Technology, Vol. 12, No. 4, April 2002, pp. 227-237
A Computational Memory Architecture for MPEG-4 Applications with Mobile Devices
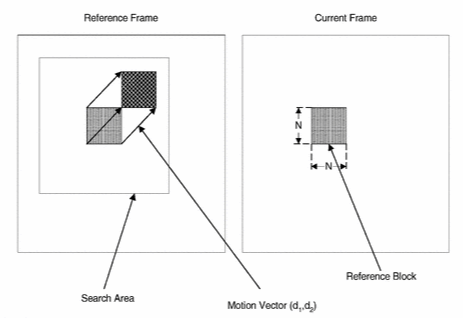
This paper presents a Computational Memory architecture for MPEG-4 applications with mobile devices. The proposed architecture is used for real-time block-based motion estimation, which is the most computational intensive task in the video encoder. It uses the exhaustive block-matching algorithm (EBMA) for motion estimation. The proposed architecture consists of embedded SRAMs and a number of block-matching units working in parallel to process video data while stored in the memory. The block-matching units access the embedded SRAMs simultaneously, which increases the speed of the architecture.
The architecture processes CIF format video sequences (i.e., the frame size is 352 × 288 pixels) with block size of 16 × 16 pixels and ±15 pixels search range. The proposed architecture has been designed, prototyped, and simulated for 0.18 μm TSMC CMOS technology. The simulation shows that the proposed architectures processes up to 126 CIF frames per second with clock frequency 100 MHz. The synthesized prototype of the proposed architecture includes 200 KB memory and it has an area of 33.75 mm2 and consumes 986.96 mW @100 MHz.
Mohammed Sayed , Wael Badawy, “A Computational Memory Architecture for MPEG-4 Applications with Mobile Devices,” Journal of VLSI Signal Processing Systems for Signal, Image and Video Technology – Special Issue on Digital and Computational Video , Vol. 42, No. 1, pp. 35-42, January 2006.