
Category: Journal Papers
Hierarchical Adaptive Structure Mesh for Efficient Video Coding
Wael Badawy, “Hierarchical Adaptive Structure Mesh for Efficient Video Coding,” The International Journal on Image and Video Processing, Vol. 17, November 2001
A Multiplication-Free Algorithm and A Parallel Architecture for Affine Transformation
Affine transformation is widely used in image processing. Recently, it is recommended by MPEG-4 for video motion compensation. This paper presents a novel low power parallel architecture for texture warping using affine transformation (AT). The architecture uses a novel multiplication-free algorithm that employs the algebraic properties of the AT. Low power has been achieved at different levels of the design. At the algorithmic level, replacing multiplication operations with bit shifting saves the power and delay of using a multiplier. At the architecture level, low power is achieved by using parallel computational units, where the latency constraints and/or the operating latency can be reduced. At the circuit level, using low power building blocks (such as low power adders) contributes to the power savings. The proposed architecture is used as a computational kernel in video object coders. It is compatible with MPEG-4 and VRML standards. The architecture has been prototyped in 0.6 μm CMOS technology with three layers of metal. The performance of the proposed architecture shows that it can be used in mobile and handheld applications.
Wael Badawy and Magdy Bayoumi, “A Multiplication-Free Algorithm and A Parallel Architecture for Affine Transformation,” The Journal of VLSI Signal Processing-Systems, Kluwer Academic Publishers, Vol. 31, No 2, May 2002, pp. 173-184.

A Parallel Multiplication-Free Algorithm and Architecture for Affine-based Motion Compensation
Affine transformation is widely used in image processing. Recently, it has been recommended by MPEG-4 for video motion compensation. We present a novel low-power parallel architecture for texture warping using affine transformation (AT). The architecture uses a novel multiplication-free algorithm that employs the algebraic properties of the affine transformation. Low power has been achieved at different levels of the design. At the algorithmic level, replacing multiplication operations with bit shifting saves the power and delay of using a multiplier. At the architecture level, low power is achieved by using parallel computational units. At the circuit level, using low-power cells contributes to the power savings. The proposed architecture is used as a computational kernel in video object coders. It is compatible with MPEG-4 and virtual reality modeling language (VRML) standards. The architecture has been prototyped in 0.6-µm CMOS technology with three layers of metal. The performance of the proposed architecture shows that it can be used in mobile and handheld applications.
Wael Badawy and Magdy Bayoumi, “A Parallel Multiplication-Free Algorithm and Architecture for Affine-based Motion Compensation,” The SPIE Journal on Optical Engineering, Vol. 42 No. 1, January 2003 pp. 255 – 264

System on Chip: the Future of System Integration
System on chip:
The future of the integration paradigm
Syste`me sur une puce:
le futur du paradigme de l’inte ́gration
Wael Badawy
The increase in the number of transistors that can be integrated on a single chip allows the integration of more functions. On the other hand, time-to-market pressures require novel techniques for developing integrated circuits. System on chip is a methodology that allows the integration of several third-party cores with an embedded processor. This paper presents a tutorial for the system- on-chip methodology and presents the design tasks that are involved in developing a system on chip.
L’accroissement du nombre de transistors qu’il est possible d’inte ́grer sur une puce permet d’offrir plus de fonctionnalite ́s. D’autre part, les pressions de la mise en marche ́ rapide de celles-ci exige l’e ́laboration de techniques nouvelles de de ́veloppement de circuits inte ́gre ́s. Les syste`mes sur une puce repre ́sentent une me ́thodologie de de ́veloppement qui permet l’inte ́gration de com- posantes provenant de plusieurs de ́veloppeurs et de les combiner a` un processeur embarque ́. Cet article pre ́sente un tutoriel sur la me ́thodologie de conception de circuits sur une puce et pre ́sente les taˆches de design implique ́es dans le de ́veloppement de tels syste`mes.
Wael Badawy, “System on Chip: the Future of System Integration,” The Canadian Journal on Electrical and Computer Engineering, Vol. 27, No. 4, October 2002, pp. 149 – 154

Low power very large scale integration prototype for three-dimensional discrete wavelet transform processor with medical application
We present a low-power 3-D discrete wavelet transform processor for medical applications. The main focus is the compression of medical resonance image (MRI) data, although the system could be used as a generic compression chip. The architecture eliminates redundant filter banks by using a central control unit to dynamically adjust filter parameters. An on-chip cache is used to process block inputs minimizing result throughput. Power consumption has been kept to a minimum by placing constraints throughout the entire design process. The modular processor has been prototyped using 0.6-μm complementary metal oxide semiconductor (CMOS) (three metal) technology. It has been simulated at the functional, circuit, and physical levels. The performance measures of the prototype, area, time delay, power, and utilization have been evaluated. The prototype operates at an estimated frequency of 272 MHz and dissipates 0.5 W of power.
Wael Badawy, Michael Talley, Guoqing Zhang, Michael Weeks, and Magdy Bayoumi, “Low Power Very Large Scale Integration Prototype for Three-Dimensional Discrete Wavelet Transform Processor with Medical Applications,” The SPIE Journal on Electronic Imaging, Vol. 12, Issue 2, April 2003, pp. 270 – 277.

A Low Power Architecture for HASM Motion Tracking
This paper proposes low power VLSI architecture for motion tracking that can be used in online video applications such as in MPEG and VRML. The proposed architecture uses a hierarchical adaptive structured mesh (HASM) concept that generates a content-based video representation. The developed architecture shows the significant reducing of power consumption that is inherited in the HASM concept. The proposed architecture consists of two units: a motion estimation and motion compensation units.
The motion estimation (ME) architecture generates a progressive mesh code that represents a mesh topology and its motion vectors. ME reduces the power consumption since it (1) implements a successive splitting strategy to generate the mesh topology. The successive split allows the pipelined implementation of the processing elements. (2) It approximates the mesh nodes motion vector by using the three step search algorithm. (3) and it uses parallel units that reduce the power consumption at a fixed throughput.
The motion compensation (MC) architecture processes a reference frame, mesh nodes and motion vectors to predict a video frame using affine transformation to warp the texture with different mesh patches. The MC reduces the power consumption since it uses (1) a multiplication-free algorithm for affine transformation. (2) It uses parallel threads in which each thread implements a pipelined chain of scalable affine units to compute the affine transformation of each patch.
The architecture has been prototyped using top-down low-power design methodology. The performance of the architecture has been analyzed in terms of video construction quality, power and delay.
A Low Power Architecture for HASM Motion Tracking
|
Wael Badawy and Magdy Bayoumi, “A Low Power VLSI Architecture for Mesh-based Video Motion Tracking,” The Journal of VLSI Signal Processing-Systems, Kluwer Academic Publishers, invited.
A Low Power VLSI Architecture for Mesh-based Video Motion Tracking
This paper proposes a low-power very large-scale integration (VLSI) architecture for motion tracking. It uses a hierarchical adaptive structured mesh that generates a content-based video representation. The proposed mesh is a coarse-to-fine hierarchical two-dimensional mesh that is formed by recursive triangulation of the initial coarse mesh geometry. The structured mesh offers a significant reduction in the number of bits that describe the mesh topology. The motion of the mesh nodes represents the deformation of the video object. The architecture consists of motion estimation and motion compensation units. The motion estimation architecture generates a progressive mesh code and the motion vectors of the mesh nodes. It reduces the power consumption, uses a simpler approach for mesh construction, approximates the mesh nodes motion vector by using the three step search algorithm and uses a parallel motion estimation core to evaluate the mesh nodes motion vectors. Moreover, it maximizes the lifetime of the internal buffers. The motion compensation architecture uses a multiplication-free algorithm for affine transformation, which significantly reduces the complexity of the motion compensation architecture. Moreover, using pipelined affine units contributes to the power savings. The video motion compensation architecture processes a reference frame, mesh nodes and motion vectors to predict a video frame. It implements parallel threads in which each thread implements a pipelined chain of scalable affine units. This motion compensation algorithm allows the use of one simple warping unit to map a hierarchical structure. The affine unit warps the texture of a patch at any level of hierarchical mesh independently. The processor uses a memory serialization unit, which interfaces the memory to the parallel units. The architecture has been prototyped using top-down low-power design methodology. The performance analysis shows that this processor can be used in online object-based video applications such as in MPEG and VRML.
Published in:
Circuits and Systems II: Analog and Digital Signal Processing, IEEE Transactions on (Volume:49 , Issue: 7 )
- Page(s):
- 488 – 504
- ISSN :
- 1057-7130
- INSPEC Accession Number:
- 7460367
- DOI:
- 10.1109/TCSII.2002.805248
- Date of Publication :
- Jul 2002
- Date of Current Version :
- 10 December 2002
- Issue Date :
- Jul 2002
- Sponsored by :
- IEEE Circuits and Systems Society
- Publisher:
- IEEE
Wael Badawy and Magdy Bayoumi, “A Low Power VLSI Architecture for Mesh-based Video Motion Tracking,” The IEEE Transactions on Circuits and Systems II, Vol. 49, July 2002, pp. 488-504.
A VLSI Architecture for Video Object Motion Estimation Using a 2D Hierarchical Mesh Model
This paper proposes a novel hierarchical mesh-based video object model and a motion estimation architecture that generates a content-based video object representation. The 2D mesh-based video object is represented using two layers: an alpha plane and a texture. The alpha plane consists of two layers: (1) a mesh layer and (2) a binary layer that defines the object boundary. The texture defines the object’s colors. A new hierarchical adaptive structured mesh represents the mesh layer. The proposed mesh is a coarse-to-fine hierarchical 2D mesh that is formed by recursive triangulation of the initial coarse mesh geometry. The proposed technique reduces the mesh code size and captures the mesh dynamics. The proposed motion estimation architecture generates a progressive mesh code and the motion vectors of the mesh nodes. The performance analysis for the proposed video object representation and the proposed motion estimation architecture shows that they are suitable for very low bit rate online mobile applications and the motion estimation architecture can be used as a building block for MPEG4 codec.
Wael Badawy, “A VLSI Architecture for Video Object Motion Estimation Using a 2D Hierarchical Mesh Model,” Microprocessors and Microsystems, Vol. 27, No. 3, April 2003, pp 131 – 140, invited.

Applying FEA to Investigate the performance of Electrostatic Comb-Drive Actuators Utilized by on-a-chip systems
This study focuses on investigating the design parameters of lateral electrostatic comb-drive actuators, where the effect of these parameters on the actuation performance is explored using finite element analysis (FEA). This level of analysis is essential to the design process of system-on-a-chip microelectromechanical systems (MEMS) applications, where a comb drive can represent the main source of actuation within the chip system. Of particular interest to this study is the application of the electrostatic comb- drive motor as a fluidic pump in on-a-chip systems used for drug delivery or in cooling of microprocessors used in space vehicles. The commercial FE package ANSYS is utilized to construct a robust comb-drive model and solve its multiphysics interaction problem using the direct coupled-field analysis. In this model, the thickness, gap and overlap of the comb fingers are varied. The design of this model is also modulated to account for changes in the number of comb fingers and the applied driving voltage. The calculated comb displacement and generated electrostatic force are shown to be directly proportional to the number of comb fingers. Moreover, the generated electrostatic force is found to be inversely proportional to the gap between the comb fingers. As the thickness of these fingers increases, the displacement is found to increase for a given value of the driving voltage. The electrostatic force is also shown to be proportional to the offset (i.e., overlap) value between the fingers. To facilitate the use of the current study results in optimizing the design process of comb drives, an effort is made in the current work to condense these results into a compact nondimensional form that correlates the geometric and electrical parameters of the studied comb drive to the resulting displacement and force.
Cette e ́tude s’inte ́resse a` l’e ́tude par la me ́thode des e ́le ́ments finis des parame`tres de design des actionneurs e ́lectrostatiques late ́raux en peigne de meˆme que l’effet des parame`tres sur les performances des actionneurs. Une telle finesse d’analyse est ne ́cessaire a` la conception de dispositifs inte ́gre ́s dans les applications de syste`mes micro-e ́lectro-me ́caniques (MEMS) car l’entraˆınement en peigne peut constituer la principale source d’actionnement dans le syste`me inte ́gre ́. L’inte ́reˆt principal de cette approche est qu’elle peut s’appliquer a` la conception de moteurs a` peignes e ́lectrostatiques pour les pompes a` fluides dans les syste`mes sur une puce inte ́gre ́s pour la distribution de doses de me ́dicaments ou pour le refroidissement de micro-processeurs dans les ve ́hicules spatiaux. Un mode`le robuste de l’entraˆınement en peigne est construit graˆce au package logiciel d’e ́le ́ments finis ANSYS et pour re ́soudre le proble`me d’interaction multi-physique graˆce a` une analyse directe de champ couple ́. Dans le mode`le, on peut modifier l’e ́paisseur, l’espacement et le chevauchement entre les dents du peigne. La conception du mode`le prend aussi en compte la variation du nombre de dents du peigne et des valeurs de la tension d’entraˆınement. Le calcul des de ́placements des dents du peigne et de la force e ́lectrostatique ge ́ne ́re ́e montre leur de ́pendance directement proportionelle au nombre de dents du peigne. De plus, la force e ́lectrostatique ge ́ne ́re ́e est pour sa part inversement proportionnelle a` l’espacement entre les dents du peigne. Pour une valeur fixe de la tension d’entraˆınement, le de ́placement augmente avec l’e ́paisseur des dents du peigne. La force e ́lectrostatique est aussi proportionnelle a` l’offset entre les dents. L’utilisation de cette e ́tude pour l’optimisation du processus de conception de syste`mes d’entraˆınement a` peigne est facilite ́e par la pre ́sentation d’une forme compacte adimensionnelle corre ́lant les parame`tres ge ́ome ́triques et e ́lectriques de l’entraˆınement a` l’e ́tude au de ́placement et a` la force re ́sultants.
Hesham Ahmed, Walied Moussa, Wael Badawy, Medhat Moussa, “Applying FEA to Investigate the performance of Electrostatic Comb-Drive Actuators Utilized by on-a-chip systems” The Canadian Journal on Electrical and Computer Engineering, Vol. 27, No. 4, October 2002, pp. 195 – 200. Abstract
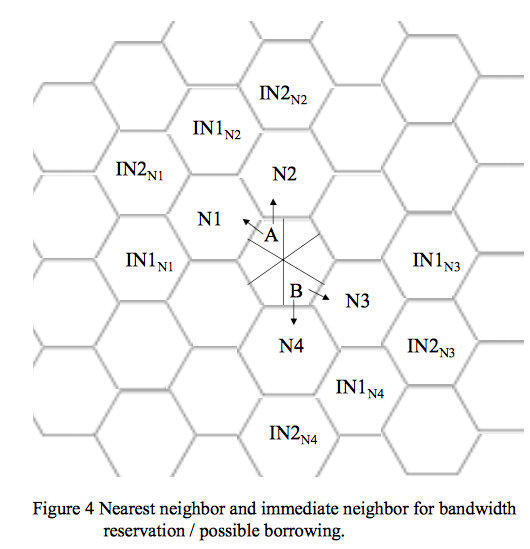
An Optimal Call Admission and Bandwidth Reservation Scheme for Future Wireless Networks
The next generation wireless networks promises availability of a wide variety of services. To be supported successfully, it is necessary to provide quality of service (QoS) between end-systems with the resources whose cost is discouragingly high. This paper proposes a new scheme for call admission and bandwidth reservation for the next generation wireless networks. The proposed scheme OPBR (optimal cell partition based bandwidth reservation) does an optimal partitioning of the cell to give high degree of call admission and successful handoff. In addition it offers effective bandwidth utilization and guarantee QoS. The performance of the scheme is done by analytical modeling and simulation experiments. A comparison with two different schemes (PBR and adaptive reservation) shows desirable results can be achieved by proposed scheme with better performance for various QoS parameters.
Download An Optimal Call Admission and Bandwidth Reservation Scheme for Future Wireless Networks
Mehboob Alam, Wael Badawy, Graham Jullien, “A Optimal Call Admission and Bandwidth Reservation Scheme for Future Wireless Networks,” Journal of Internet Technology, Vol. 4, No. 3, pp. 163-169, ISSN 1607-9264