
Category: Journal Papers

Error-Free Computation of Daubechies Wavelets for Image Compression Applications
A novel encoding scheme for Daubechies wavelets is proposed. The technique eliminates the requirements to approximate the transformation matrix elements; rather, by using algebraic integers, it is possible to obtain exact representations for them. As a result, error-free calculations up to the final reconstruction step can be achieved, which provides considerable improvement in image reconstruction accuracy.
Published in:
Electronics Letters (Volume:39 , Issue: 5 )
- Page(s):
- 428 – 429
- ISSN :
- 0013-5194
- INSPEC Accession Number:
- 7564225
- DOI:
- 10.1049/el:20030318
- Date of Publication :
- 6 Mar 2003
- Date of Current Version :
- 02 April 2003
- Issue Date :
- 6 Mar 2003
- Sponsored by :
- Institution of Engineering and Technology
- Publisher:
- IET
K. A. Wahid, V. S. Dimitrov, G. A. Jullien and W. Badawy, “Error-Free Computation of Daubechies Wavelets for Image Compression Applications,” IEE Electronics Letters, Vol. 39, Issue 5 , 6 March 2003, pp. 428 -429
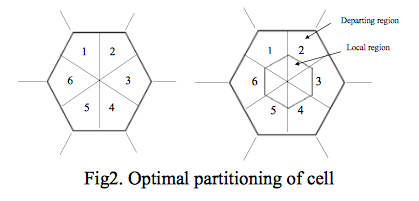
A New Call Admission and bandwidth reservation Scheme for Future Wireless Networks
The paper proposes a new scheme for call admission and bandwidth reservation for the next generation wireless networks. The proposed scheme OPBR (optimal cell partition based bandwidth reservation) does an optimal partitioning of the cell to give high degree of call admission and successful handoff. In addition it offers effective bandwidth utilization and guarantee QoS. The performance of the scheme is done by analytical modeling and simulation experiments. A comparison with two different schemes (PBR and adaptive reservation) shows desirable results can be achieved by proposed scheme with better performance for various QoS parameters.
Download A New Call Admission and Bandwidth Reservation Scheme for Future Wireless Networks
Mehboob Alam, Wael Badawy, Graham Jullien, “A New Call Admission and bandwidth reservation Scheme for Future Wireless Networks,” WSEAS Transactions on Communications, Vol. 1, Issue 1, pp. 197-203, ISSN 1109-2742

Sensing methods of Dielectrophories from Bulky Instruments to Lab-on-a-chip
Recently, the sensing methods for dielectrophoresis (DEP) have been changed from bulky instruments to lab-on-a-chip. Lab-on-a-chip based the dielectrophoresis phenomenon holds the promise to give biology the advantage of miniaturization for carrying out complex experiments. However, until now, there is an unmet need for lab-on-a-chip to effectively deal with the biological systems at the cell level.
Published in:
Circuits and Systems Magazine, IEEE (Volume:4 , Issue: 3 )
- Page(s):
- 5 – 15
- ISSN :
- 1531-636X
- INSPEC Accession Number:
- 8135939
- DOI:
- 10.1109/MCAS.2004.1337805
- Date of Publication :
- Third Quarter 2004
- Date of Current Version :
- 04 October 2004
- Issue Date :
- Third Quarter 2004
- Sponsored by :
- IEEE Circuits and Systems Society
- Publisher:
- IEEE
Yehya H. Ghallab, and Wael Badawy, “Sensing methods of Dielectrophories from Bulky Instruments to Lab-on-a-chip,” IEEE Circuit and Systems, Vol. 4, Issue 3, 2004

A Low Power Architecture for HASM Motion Tracking
This paper proposes low power VLSI architecture for motion tracking that can be used in online video applications such as in MPEG and VRML. The proposed architecture uses a hierarchical adaptive structured mesh (HASM) concept that generates a content-based video representation. The developed architecture shows the significant reducing of power consumption that is inherited in the HASM concept. The proposed architecture consists of two units: a motion estimation and motion compensation units.
The motion estimation (ME) architecture generates a progressive mesh code that represents a mesh topology and its motion vectors. ME reduces the power consumption since it (1) implements a successive splitting strategy to generate the mesh topology. The successive split allows the pipelined implementation of the processing elements. (2) It approximates the mesh nodes motion vector by using the three step search algorithm. (3) and it uses parallel units that reduce the power consumption at a fixed throughput.
The motion compensation (MC) architecture processes a reference frame, mesh nodes and motion vectors to predict a video frame using affine transformation to warp the texture with different mesh patches. The MC reduces the power consumption since it uses (1) a multiplication-free algorithm for affine transformation. (2) It uses parallel threads in which each thread implements a pipelined chain of scalable affine units to compute the affine transformation of each patch.
The architecture has been prototyped using top-down low-power design methodology. The performance of the architecture has been analyzed in terms of video construction quality, power and delay.
Wael Badawy and Magdy Bayoumi “A Low Power Architecture for HASM Motion Tracking,” The Journal of VLSI Signal Processing Systems for Signal, Image, and Video Technology, May 2004, Vol. 37, Issue 1, pp. 111-127
Architectures for Finite Radon Transform
Two VLSI architectures for the finite Radon transform are presented. The first is a reference architecture using memory blocks and the second is a memoryless architecture. The proposed architectures use 7×7 size image blocks and are prototyped for processing the CIF image sequence. The simulation and synthesis results show that the core speeds of the two proposed architectures are around 100 and 82 MHz, respectively.
Published in:
Electronics Letters (Volume:40 , Issue: 15 )
- Page(s):
- 931 – 932
- ISSN :
- 0013-5194
- INSPEC Accession Number:
- 8068176
- DOI:
- 10.1049/el:20040566
- Date of Publication :
- 22 July 2004
- Date of Current Version :
- 02 August 2004
- Issue Date :
- 22 July 2004
- Sponsored by :
- Institution of Engineering and Technology
- Publisher:
- IET
C. A. Rahman and W. Badawy, “Architectures for Finite Radon Transform“, The IEE Electronics Letters, Vol. 40, Issue 15, July 2004, pp. 931-932.

A Computational RAM (C-RAM) Architecture for Real-Time Mesh-Based Video Motion Tracking: Part II Motion Compensation
This paper presents a new Computational-RAM (C-RAM) architecture for real-time mesh-based video motion tracking. In Part 1, the motion estimation part of the proposed architecture is presented. Here in Part 2, a new C-RAM mesh-based motion compensation architecture is presented. The input data to the architecture is the mesh nodes motion vectors and the reference frame and the output data is the compensated (i.e., predicted) frame. The architecture uses the affine transformation for warping the deformed patches in the reference frame into the undeformed patches in the current frame. The architecture computes the affine parameters using a multiplication-free algorithm. The reference and current frames are stored in embedded S-RAMs generated with Virage™ Memory Compiler. The proposed motion compensation architecture has been prototyped, simulated and synthesized using the TSMC 0.18 μm CMOS technology. Using 100 MHz clock frequency, the proposed architecture processes one CIF video frame (i.e., 352×288 pixels) in 0.59 ms, which means it can process up to 1694 frames per second. The core area of the proposed motion compensation architecture is 28.04 mm2 and it consumes 31.15 mW.
Mohammed Sayed and Wael Badawy, “A Computational RAM (C-RAM) Architecture for Real-Time Mesh-Based Video Motion Tracking: Part II Motion Compensation,” Journal of Circuits, Systems and Computer, Vol. 13, Issue 6, December 2004, pp. 1217-1232.
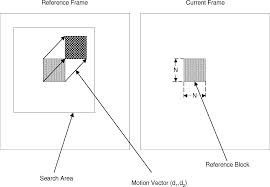
A Computational RAM (C-RAM) Architecture for Real-Time Mesh-Based Video Motion Tracking: Part I Motion Estimation,
This paper presents a new Computational-RAM (C-RAM) architecture for real-time mesh-based video motion tracking. The motion tracking consists of two operations: mesh-based motion estimation and compensation. The proposed motion estimation architecture is presented in Part 1 and the proposed motion compensation architecture is presented in Part 2. The motion estimation architecture stores two frames and computes motion vectors for a regular triangular mesh structure as defined by MPEG-4 Part 2.1 The motion estimation architecture uses the block-matching algorithm (BMA) to estimate the vertical and horizontal motion vectors for each mesh node. Parallel and pipelined implementations have been used to overcome the huge computational requirements of the motion estimation process. The two frames are stored in embedded S-RAMs generated with Virage™ Memory Compiler. The proposed motion estimation architecture has been prototyped, simulated and synthesized using the TSMC 0.18 μm CMOS technology. At 100 MHz clock frequency, the proposed architecture processes one CIF video frame (i.e., 352×288 pixels) in 1.48 ms, which means it can process up to 675 frames per second. The core area of the proposed motion estimation architecture is 24.58 mm2 and it consumes 46.26 mW.
Read More: https://www.worldscientific.com/doi/abs/10.1142/S0218126604001921
Mohammed Sayed and Wael Badawy, “A Computational RAM (C-RAM) Architecture for Real-Time Mesh-Based Video Motion Tracking: Part I Motion Estimation,” Journal of Circuits, Systems and Computers, Vol. 13, Issue 6, December 2004, pp. 1203-1216.

A new time distributed DCT architecture for MPEG-4 hardware reference model
This paper presents the design of a new time distributed architecture (TDA) which outlines the architecture (ISO/IEC JTC1/SC29/WG11 MPEG2002/M8565) submitted to MPEG4 Part9 committee and included in the ISO/IEC JTC1/SC29/WG11 MPEG2002/9115N document. The proposed TDA optimizes the two-dimensional discrete cosine transform (2-D-DCT) architecture performance. It uses a time distribution mechanism to exploit the computational redundancy within the inner product computation module. The application specific requirements of input, output and coefficients word length are met by scheduling the input data. The coefficient matrix uses linear mappings to assign necessary computation to processor elements in both space and time domains. The performance analysis shows performance savings in excess of 96% as compared to the direct implementation and more than 71% as compared to other optimized application specific architectures for DCT.
Published in:
Circuits and Systems for Video Technology, IEEE Transactions on (Volume:15 , Issue: 5 )
- Page(s):
- 726 – 730
- ISSN :
- 1051-8215
- INSPEC Accession Number:
- 8422879
- DOI:
- 10.1109/TCSVT.2005.846429
- Date of Publication :
- May 2005
- Date of Current Version :
- 02 May 2005
- Issue Date :
- May 2005
- Sponsored by :
- IEEE Circuits and Systems Society
- Publisher:
- IEEE
Alam, M.; Badawy, W.; Jullien, G.; “A new time distributed DCT architecture for MPEG-4 hardware reference model,” IEEE Circuits and Systems for Video Technology, Volume 15, Issue 5, May 2005, pp. 726 – 730.
Review of Principles of verifiable RTL design
By Lionel Bening and Harry Foster, Kluwer Academic Publishers, 2000.
Using verifiable RTL design, an engineer can add or improve the use of cycle-based simulation, two-state simulation, formal equivalence checking, and model checking in the traditional verification flow. Furthermore, a verifiable RTL coding methodology permits the engineer to achieve greater verification coverage in minimal time, enhances cooperation and support for multiple EDA tools within the flow, clarifies RTL design intent, and facilitates emerging verification processes.
This book addresses verification of synchronous designs. It provides a comprehensive understanding of various verification processes from conceptual and practical approaches. The concepts presented in this book are drawn from author experience with large-scale system design projects. It draws a technique methodology for verifiable RTL coding. The book is divided into nine chapters as follows. Chapter 1 provides a short introduction of this book. Chapter 2 introduces four principles of RTL design (fundamental verification principle, retain useful information principle, orthogonal verification principle, and functional observation principle) and issues related to verifiable RTL (design specification, test strategies, coverage analysis, event monitoring, and assertion checking). Chapter 3 introduces the basics of the RTL methodology and addresses the problem of complexity due to competing tool coding requirements. It introduces a simplified and tool-efficient Verilog RTL verifiable subset using an object-oriented hardware design (OOHD) methodology. Moreover, it details a linting methodology, which is used to enforce project-specific coding rules and tool performance checks. Chapter 4 presents the history of logic simulation, followed by a discussion on applying RTL simulation at various stages within the design phase. Chapter 5 discusses RTL and the formal verification process. It presents the concept of finite state machine FSM and its analysis and applicability to proving machine equivalence and FSM properties. Chapter 6 discusses ideas on verifiable RTL style. Chapter 7 provides examples on the common mistakes that are involved with projects, designers, and EDA verification tool developers. Chapter 8 presents a tutorial on Verilog language elements that can be used to build a verifiable RTL model. Chapter 9 summarizes the 21 fundamental principles of verifiable RTL Design, which are discussed throughout the book.
This book is considered one of the milestones for verifiable RTL design. It shows an efficient methodology for writing a verifiable RTL, and it defines guidelines for large-scale systems. I believe that every engineer working in the area of RTL design should read this book.
Wael Badawy, “Principles of verifiable RTL design“, IEEE Circuits and Devices Magazine, Vol. 18, Issue 1, January 2002, pp. 26 -27
Algorithm-Based Low Power VLSI Architecture For 2d-Mesh Video Object Motion Tracking
The new VLSI architecture for video object (VO) motion tracking uses a novel hierarchical adaptive structured mesh topology. The structured mesh offers a significant reduction in the number of bits that describe the mesh topology. The motion of the mesh nodes represents the deformation of the VO. Motion compensation is performed using a multiplication-free algorithm for affine transformation, significantly reducing the decoder architecture complexity. Pipelining the affine unit contributes a considerable power saving. The VO motion-tracking architecture is based on a new algorithm. It consists of two main parts: a video object motion-estimation unit (VOME) and a video object motion-compensation unit (VOMC). The VOME processes two consequent frames to generate a hierarchical adaptive structured mesh and the motion vectors of the mesh nodes. It implements parallel block matching motion-estimation units to optimize the latency. The VOMC processes a reference frame, mesh nodes and motion vectors to predict a video frame. It implements parallel threads in which each thread implements a pipelined chain of scalable affine units. This motion-compensation algorithm allows the use of one simple warping unit to map a hierarchical structure. The affine unit warps the texture of a patch at any level of hierarchical mesh independently. The processor uses a memory serialization unit, which interfaces the memory to the parallel units. The architecture has been prototyped using top-down low-power design methodology. Performance analysis shows that this processor can be used in online object-based video applications such as MPEG-4 and VRML
Wael Badawy and Magdy Bayoumi, “Algorithm-Based Low Power VLSI Architecture For 2d-Mesh Video Object Motion Tracking,” The IEEE Transaction on Circuits and Systems for Video Technology, Vol. 12, No. 4, April 2002, pp. 227-237